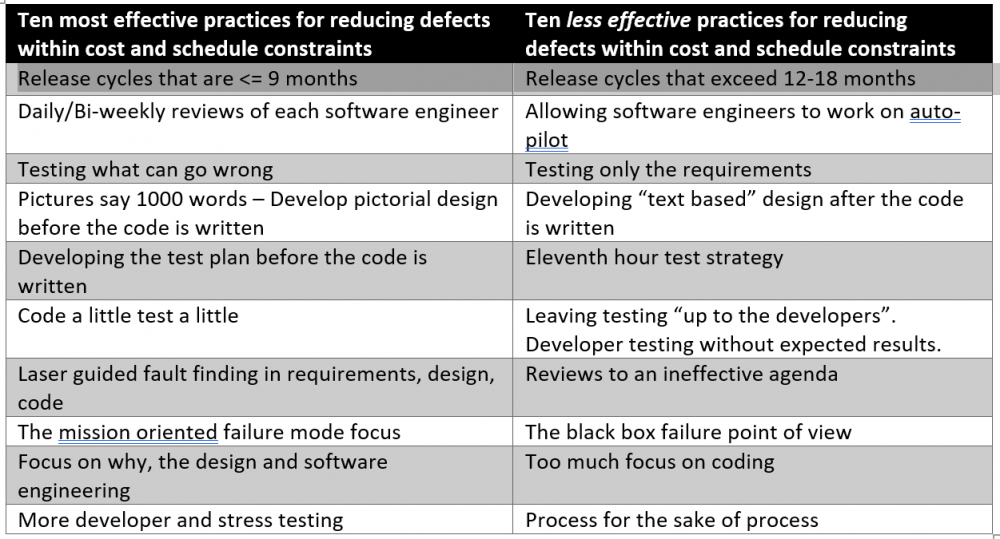
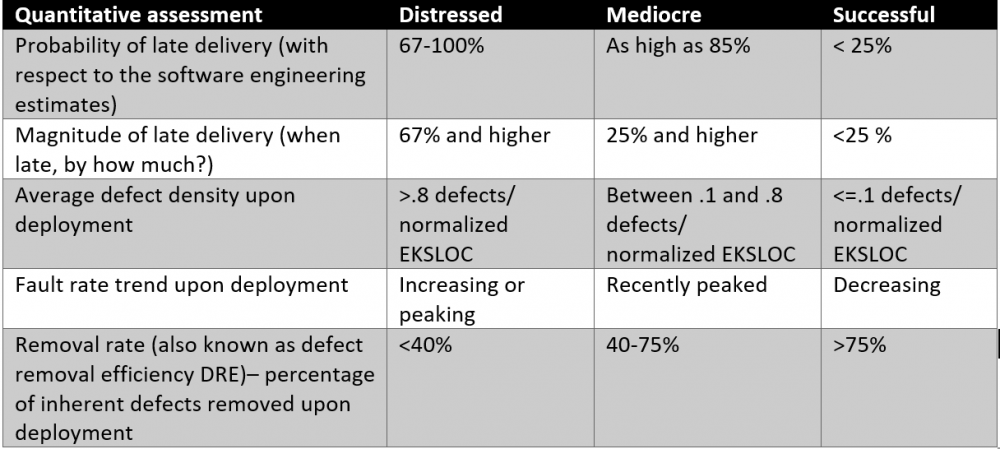
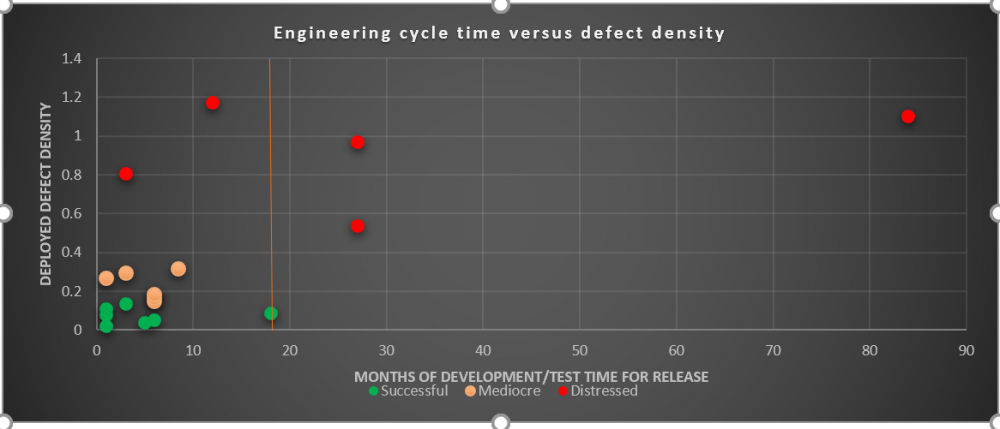
Engineering cycle time versus defect density
The bad practice of “aiming big” with longer release cycles started in the early 1980s when I started working as a software engineer. So, why are longer release cycles problematic? In summary, longer release cycles are more likely to result in a significantly late software project. Our benchmarking data[1] clearly shows that whenever a software project becomes late, the reliability of the software drops significantly since the software development and testing efforts are almost always compromised. These are just a few reasons why longer release cycles cause both late software and unreliable software:
• Software releases become late one day at a time. The longer the release cycle – the more likely software people waste one day at a time.
• “Kick the can” mindset by all of the engineerings leads to late starts
• Software people think they have plenty of time to make up for the late start. In our database of software projects, there were no cases in which anyone made up for the lost time.
• Similar mindset to the college student who is given a month to do a project but starts working on it the night before.
• People tend to not think about anything that’s not due this year
• If they aren’t thinking about it then it’s not likely that they are working towards it
• Longer release cycles mean it takes a lot longer to find out the software wasn’t what the customer wanted, misunderstandings about the requirements or serious design flaws
So the question is – how does one reduce the engineering cycle so as to “aim small – miss small”? There is one way to definitely NOT shorten the release cycle and that is to arbitrarily chop the release time but not the scope. Shortening the release cycle means splitting the functionality that used to be in one big release into smaller releases. It does not mean taking less time to do develop the same functionality. If that worked, I wouldn’t be writing this paper. The right answer depends on how long the cycle is now. If the engineering cycle is well beyond 18 months, trying to shorten it to a few months maybe a bit aggressive. Reducing the cycle time to not more than a year may be a more reasonable first step. More than one pass may be required to achieve the ideal release cycle.
One alternative is to have alternating feature and bug fix releases. For example, each is 8-9 months apart but the feature releases and bug fix releases are 4-5 months from each other. That means that the customer is getting something every 4-5 months. The odd-numbered releases, for example, can be new feature releases while the even-numbered releases can be bug fixes.
The biggest obstacle to reducing the engineering cycles is the culture change and dealing with the many bad excuses for the long cycles. Software engineers may complain about the “additional overhead” of smaller releases as opposed to larger less frequent releases. This is largely nonsense. If there is substantial overhead in “releasing” the software then the software group isn’t doing what they are supposed to do throughout development to prepare for a release. Marketing people tend to have the biggest angst about shorter releases because they fear that whatever does not make the early release will never happen. Or they are simply unwilling to prioritize any feature. If the release cycle is set to be smaller AND engineering doesn’t backtrack on the schedule by allowing extra scope, the marketing people will eventually realize that this is their best bet for getting features predictably on time.
Perspective from an Experienced Engineering Leader
“Without question, delivering smaller, more frequent releases is more effective than aggregating features, functions, bug fixes, etc. into larger releases that require eighteen months or more to complete. There are a number of reasons for this but I will focus on a few which I believe have the greatest impact. Shorter development cycles have the benefit of 1) constraining the scope of any one release; 2) establishing a cadence of regular, timely releases; and 3) building the capabilities of the development team.
Limiting releases to a defined time period of several months has the effect of constraining scope. High predictability in development starts with an accurate estimation of resources and time required regardless of the task. Estimating smaller scope tasks is inherently easier than estimating large, long-duration often inter-related activities. Likewise, the accuracy of estimation is also improved by the build-up of experience and historic data which comes with more frequent release cycles. The constrained scope has the effect of limiting the extent of unintended consequences arising from design changes as individuals are more likely to analyze and comprehend the impact of additions or modifications they are making across the broader codebase. Larger scope directly translates to increased complexity.
Regular, timely releases instill confidence in the broader organization (e.g. Marketing, Customer Support, Manufacturing, etc.) that there will be opportunities subsequent to the currently planned release to address their needs. The increased confidence has the effect of reducing the pressure to expand the scope of the “current” release due to a lack of certainty regarding the timing of the “next” release. Regular releases also provide a ready vehicle for addressing emergent concerns such as safety issues or security vulnerabilities without significant change to the program underway or an unacceptable delay in delivering a resolution to the market.
Software development requires a high degree of teamwork. Like any other activity which involves teams, the team gets better with practice. Instituting a release cycle measure in months allows the team to fully exercise all elements of the development process – architecture design, estimating, resource planning, coding, testing, documentation, and release delivery at least once every year and ideally, two to three times per year. All of these activities improve with repetition. It’s also important to keep in mind that as a person progresses through his or her career, they often change roles every two to three years. With longer release cycles, it’s quite likely that persons in key roles such as Product Owner, Architect, Scrum Master, Program Manager, etc. may have experienced only one or, at most, two releases before they transition to a new role if the typical release timeline is 18+ months.
For these reasons, I highly recommend instituting a regular rhythm of major release projects planned for 9-12 month duration with minor updates and bug fixes planned for 3-6 month duration depending on the nature of your product. Doing this will improve code quality and team productivity. “
Tom Neufelder, Retired Senior Vice President Philips Healthcare – Diagnostics Imaging
Next month we will discuss the second ineffective software development practice – allowing software engineers to work on auto-pilot.
[1]”The Cold Hard Truth About Reliable Software”, edition 6i, 2019, Ann Marie Neufelder